数据采集部分
分析页面
找一个歌手的主页进去,发现分四个标签:热门作品、所有专辑、相关MV和艺人介绍,没有全部歌曲的页面,不过既然有全部专辑,也就相当于有了所有歌曲,可以通过遍历所有专辑来获得每个专辑中的歌曲,再合并成一个大列表,这样就能间接的取到全部的歌曲id
得到歌曲id以后,通过请求每个歌曲url取到页面,然后进行主要数据的提取,评论部分可以拎出来单做,歌词的获取需要处理(要点击展开才能得到全部);url由 https://music.163.com/路径?参数组成,其中路径和参数部分为:
- 所有专辑列表:
artist/album?id=<歌手id>&limit=<数量>&offset=0 - 专辑信息页:
album?id=<专辑id> - 歌曲信息页:
song?id=<歌曲id>
基本思路:
- 先通过歌手id获取所有专辑列表:需要取到歌手专辑总页数用以计算
limit参数 - 从每个专辑页中获取歌曲id:除了歌曲id,还要对专辑页做基本处理
- 拼接歌曲id为完整url,遍历访问获得信息:主要数据的提取,发送请求要有一定间隔
有了思路接下来就可以开始数据的抓取
抓取数据
这里使用了selenium+chromedriver,本以为用requests库就能解决,但发现页面用了iframe(页面内的框架),直接访问会取不到,需要用selenium的switch_to.frame方法 ;用chrome抓包可以看到请求头,复制下来在代码中伪造浏览器时用(可以用Fiddler模拟请求发送,确认响应内容)
为了不重复访问相同页面,要有个缓存处理,即页面第一次访问时保存到本地,下次如果再访问直接从本地取,这样做的好处是不用每运行一次程序就要重新发送请求,但对于数据更新频繁的页面就不太适用,需要再加些监控更新的逻辑;数据存在Redis中,因为方便快,有个地方需要注意,有时发送请求后得到是页面是不完整的,这是因为有的元素还没有加载完程序就进行了下一步,所以需要设置等待的时间,这里使用的 WebDriverWait 和 expected_conditions,都是selenium自带的方法,可以确保目标数据元素能够取到
Redis的编码问题:因为redis中数据存的是bytes,在程序中取到的值也是bytes,如果要进行一些字符串(
str)操作需要用decode()转换;除了手动decode外还可以在创建redis连接对象时加入两个参数decode_responses=True和encoding='utf8',这样取到的值就是经过编码转换后的格式,不过当涉及字符串以外的数据类型时要看需使用
def process_url(url):
# 缓存检查
html = db.get('page:' + url)
if html is not None:
return html
else:
headers = "" # 自填
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument(headers)
browser = webdriver.Chrome(options=chrome_options)
try:
browser.get(url)
browser.switch_to.frame("g_iframe")
if "album" in url and "artist" not in url:
WebDriverWait(browser, 20, 0.5).until(
expected_conditions.presence_of_element_located((By.CLASS_NAME, 'cnt')))
if "song" in url:
WebDriverWait(browser, 20, 0.5).until(
expected_conditions.presence_of_element_located((By.ID, 'lyric-content')))
html = browser.page_source
db.set('page:' + url, html)
log("已做缓存处理:{}".format(url))
sleep(random() * 3)
return html
except Exception as e:
log("请求过程出错: {}".format(e))
finally:
browser.close()
处理数据
提取数据可以用很多方式:Xpath、正则、bs4、pyquery等,这里用的pyquery,像jQuery一样很方便,主要提取这几块数据:
- 专辑页:专辑id、专辑名、歌手id、歌手名、发行公司、发行日期、封面图
- 歌曲页:歌曲id、歌曲名、所属专辑名、所属专辑id、歌词、评论数
- 评论页:用户id、用户名、用户评论内容、被回复用户id、被回复用户名、被回复内容、点赞数
开始先用歌手id去访问专辑列表,因为列表一页有12张专辑,取到总页数后可以计算出url中的limit参数:(总页数+1)*12,填好参数补全url发送请求后就能取到所有专辑,打开F12找到专辑id的元素位置,在控制台用jquery测好位置就可以复制到pyquery对象中使用
def get_albums(singer_id):
# 通过歌手id获得专辑列表页数
singer_url = url_prefix + "artist/album?id={}".format(singer_id)
singer_html = process_url(singer_url)
singer_content = pq(singer_html)
album_page_count = singer_content(".u-page a:nth-last-child(2)").text()
# 检查
if album_page_count is not None:
album_page_count = int(album_page_count)
else:
log("获取页数时发生错误")
return None
# 通过页数计算专辑总数并获取
albums_url = singer_url + "&limit={}&offset=0".format((album_page_count + 1) * 12)
album_html = process_url(albums_url)
album_content = pq(album_html)
albums_ids = [album.attrib['data-res-id'] for album in album_content("#m-song-module li div a:nth-child(3)")]
return albums_ids
取到所有专辑的id后就可以开始专辑页的提取,这部分通过遍历每个专辑页面,提取基本数据,按字段存为hash类型,key名为album:<专辑id>,处理结束后并返回列表,列表中包含了专辑内所有歌曲id,
def process_album_from_albums(albums_ids):
"""
process album information,
:param albums_ids: 专辑id列表,
:return: 专辑内所有歌曲id,
"""
count = 0
songs_list = []
for album_id in albums_ids:
count += 1
log("正在处理第{}个专辑({})".format(count, album_id))
if db.hexists("album:" + album_id, "id"):
log("有缓存(已做过处理),专辑id:{}".format(album_id))
continue
else:
album_url = url_prefix + "album?id={}".format(album_id)
album_html = process_url(album_url)
album_content = pq(album_html)
head_data = album_content(".topblk")
# 专辑信息提取
sid = head_data("a").attr("href").split("=")[1]
singer_name = head_data("p:nth-child(2)").text().split(":")[1]
aid = album_id
name = head_data("div h2").text()
image_url = album_content(".j-img").attr("src").split("?")[0]
company = head_data("p:nth-child(4)").text().split(":")[1] if split_check(
head_data("p:nth-child(4)").text().split(":")) else ""
date = head_data("p:nth-child(3)").text().split(":")[1]
data = {
"singer_id": sid,
"singer_name": singer_name,
"id": aid,
"name": name,
"image_url": image_url,
"company": company.strip(),
"date": date
}
db.hmset("album:" + album_id, data)
# 歌曲id提取
songs_from_album = [song.attrib["href"].split("=")[1] for song in
album_content(".m-table tbody tr td:nth-child(2) span a")]
songs_list.extend(songs_from_album)
log("第{}个专辑 {} 处理完毕, 包含{}首歌曲".format(count, name, len(songs_from_album)))
return songs_list
拿到所有歌曲id后进行歌曲页的提取,跟专辑页类似,注意字符拼接,存储key名为song:<歌曲id>,存歌曲id、歌曲名、所属专辑名、所属专辑id、歌词、评论数;歌词获取需要处理,浏览器中是点击展开按钮后显示全部,我这里直接取展开前和展开后的部分然后拼起来,还要注意没有歌词的情况
def process_song(song_id):
"""
process song information,
:param song_id: 歌曲id,
:return: 处理状态(True or False),
"""
log("正在处理歌曲:{}".format(song_id))
if db.hexists("song:" + song_id, "id"):
log("有缓存(已做过处理),歌曲id:{}".format(song_id))
return True
else:
song_url = url_prefix + "song?id={}".format(song_id)
song_html = process_url(song_url)
song_content = pq(song_html)
head_data = song_content(".cnt")
song_name = head_data(".tit").text()
sid = head_data("p:nth-child(2) a").attr("href").split("=")[1]
album_id = head_data("p:nth-child(3) a").attr("href").split("=")[1]
lyric = process_song_lyric(song_content)
comment_count = head_data("#cnt_comment_count").text()
data = {
"id": song_id,
"name": song_name,
"singer_id": sid,
"album_id": album_id,
"lyric": lyric,
"comment_count": comment_count
}
try:
db.hmset("song:" + song_id, data)
except Exception as e:
log("song存入Redis时发生错误:{}".format(e))
return False
log("歌曲{}({})处理完毕".format(song_id, song_name))
return True
可视化部分
以歌手陈奕迅的数据为例进行一些分析:评论最热门的前n首歌曲,歌词中出现频次较高的词语,合作音乐人的统计,歌词中情绪最高的歌曲(通过snowNLP情绪判断),最后将这些数据用pyecharts生成Echarts图表
SnowNLP:一个处理中文文本内容的python类库,可以进行分词、词性标注、情感分析、提取关键词、转换拼音等处理
数据准备
找出歌手的所有歌曲,接下来:
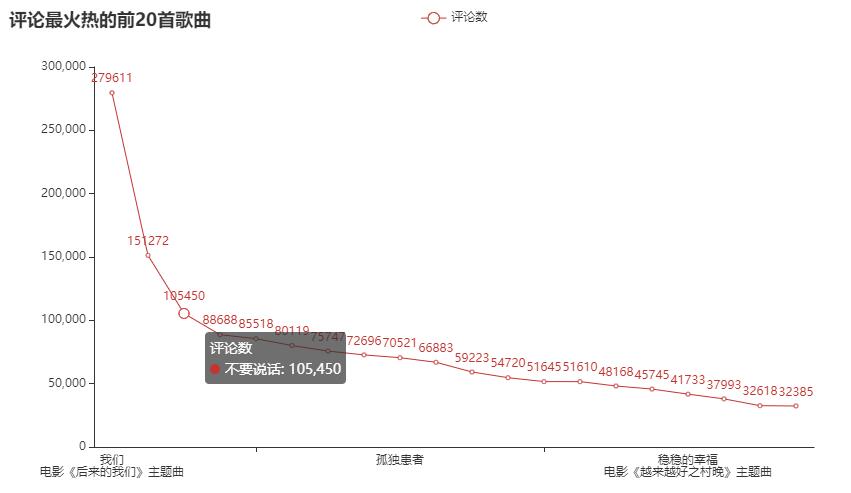
- 热门评论前n首:根据评论数进行排序,取前n首歌曲
- 取到歌词,进行基本清洗(去除空行、分离歌词与相关制作人信息),然后可以:
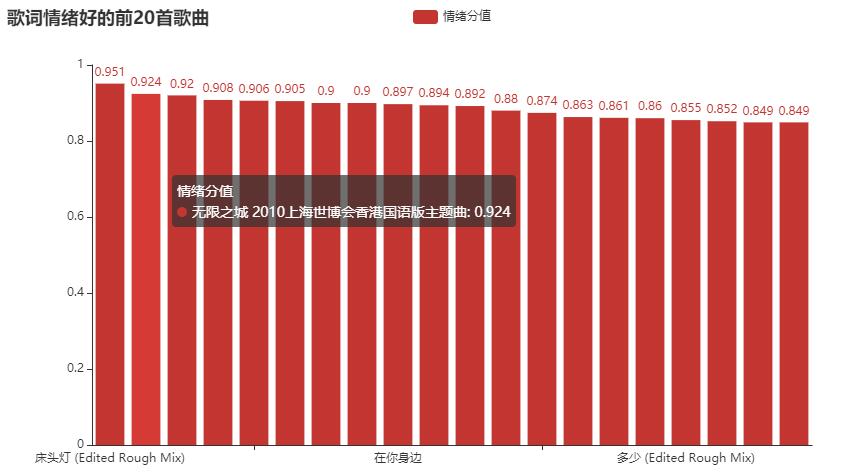
- 判断歌词情绪
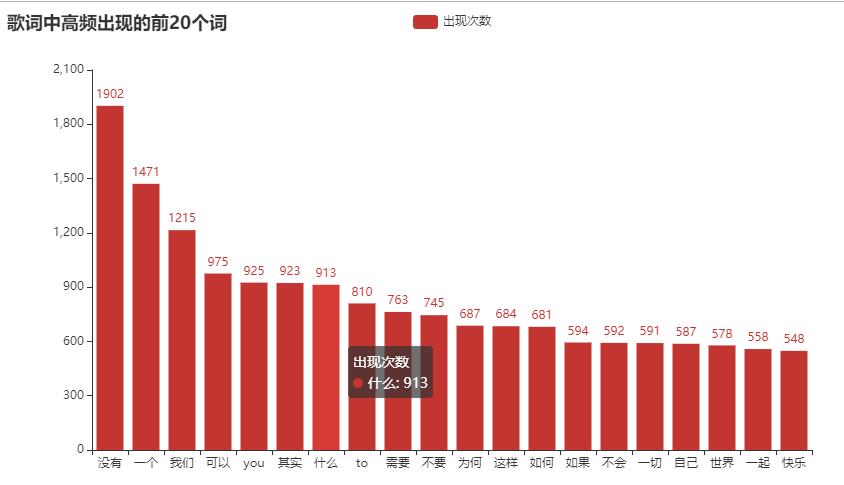
- 找出高频词语
- 统计制作人信息
# 分离歌词与制作信息
def merge_lyric_text(song):
"""
:param song: redis key name, ex: b'song:5432',
:return: (lyric text, maker info),
"""
lyric = db.hget(song, "lyric").decode("utf-8")
lyric_list = lyric.split("\n")
text = ""
info = ""
for line in lyric_list:
if line == "":
continue
if ":" in line or ":" in line:
info += line + "\n"
else:
text += line + "\n"
return text, info
自然语言处理
使用snowNLP,常用方法:words、tags、keywords、sentiments、han,分别用来分词、标词性、关键字提取、词性判断、繁体转简体,这里用到了sentiments,返回值为正面情绪的概率,接近1表正面情绪,接近0表负面情绪
# 歌词情绪判断
def process_emotion(text):
"""
:param text: lyric text,
:return: score,
"""
lyric_list = text.split("\n")
while lyric_list[-1] == "":
lyric_list.pop()
score = sum([SnowNLP(line).sentiments for line in lyric_list]) / len(lyric_list)
return score
这里分词用的jieba,用collections中封装好的计数器 Counter 来进行统计,在遍历每首歌曲后返回当前歌曲的频率统计,再把它合并到最终的计数器中,后面图表中的数据由它而来
# 统计词频
def process_frequency(text):
"""
:param text: lyric text,
:return: Counter,
"""
word_list = jieba.cut(text)
c = Counter()
for word in word_list:
if len(word) > 1 and word != '\n':
c[word] += 1
return c
生成图表
pyecharts使用起来简单方便,官方文档写的很全;这里用了条形图(Bar)、饼图(Pie)和折线图(Line),将处理好的数据进行可视化
以饼图为例,把计数器的数据 add 到图表对象中,set_global_opts 设置一些标题、边距等参数(详见文档),最后渲染成html
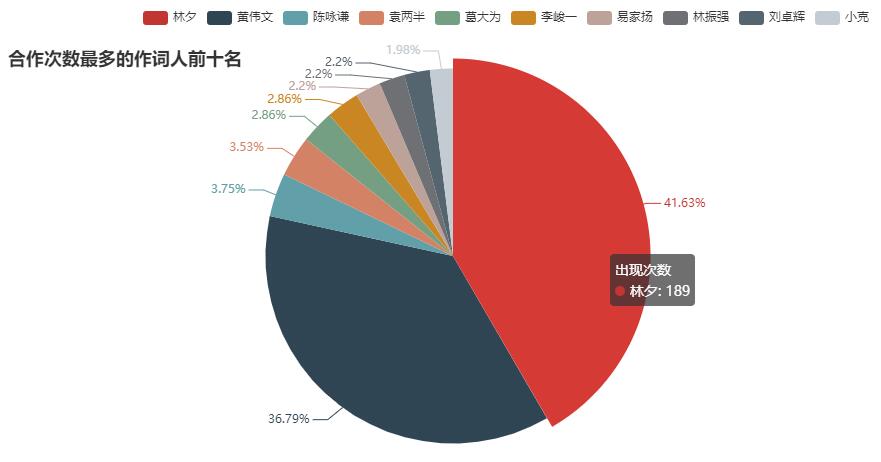
# 作词人统计
maker_pie = Pie()
maker_data = []
for name, times in maker_count.most_common(10):
maker_data.append((name, times))
maker_pie.add("出现次数", maker_data)
maker_pie.set_global_opts(title_opts=opts.TitleOpts(title="合作次数最多的作词人前十名", pos_top="8%"),
legend_opts=opts.LegendOpts(pos_left="15%"),
)
maker_pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{d}%"))
maker_pie.render("合作次数最多的作词人前十名.html")
效果如下